-
Hadoop SQL
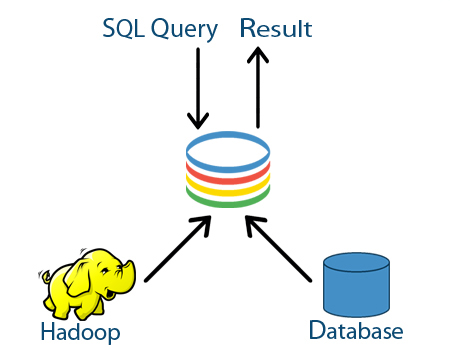
QueryIO enables you to leverage the vast and mature infrastructure built around SQL and relational databases and seamlessly integrate that with Hadoop to address Big Data Analytics needs.
Hadoop gives you power and scale via distributed storage (HDFS) and distributed computing (MapReduce). Using SQL gives you ease of use and standards. You can leverage existing Business Intelligence tools and SQL skills your organization already has to query, analyze and visualize your processed Big Data.
-
QueryIO provides On-Ingest metadata extraction service where by extended metadata can be extracted from the files on ingest and you don't need to worry about running costly batch jobs later on. This enables the unstructured data on cluster searchable readily as soon as its ingested.
Since all the metadata and tags associated with a file are kept in a relational database, you can leverage the existing infrastructure built around SQL to search the data on the hadoop cluster.
QueryIO provides an interface which you can use to register your programmatic interface for processing unstructured data on Hadoop cluster. You can then run standard SQL query which would trigger the MapReduce jobs to process the data on cluster and all the results of processing is stored in relational database, which is readily available to you for further analysis. Once the structured data is assembled, you can query, analyze and visualize this data using standard SQL syntax and other BI tools to achieve your Big Data analytics needs.
QueryIO also helps making data searchable over Hadoop cluster using SQL. To help make unstructured data searchable on Hadoop Cluster, it stores the metadata for each file stored on Hadoop in a relational database. You can further tag the data stored on hadoop cluster using its Data Tagging service. Here again the tags defined for all the files on cluster are stored in a relational database. It takes care of keeping the metadata and tags stored in database in synch with the files stored on Hadoop cluster.
 Facebook
Facebook YouTube
YouTube LinkedIn
LinkedIn Google+
Google+ Twitter
Twitter SlideShare
SlideShareQueryIO, "Big Data Intelligence" and the QueryIO Logo are trademarks of QueryIO Corporation.
Apache, Hadoop and HDFS are trademarks of The Apache Software Foundation.
QueryIO, "Big Data Intelligence" and the QueryIO Logo are trademarks of QueryIO Corporation.
Apache, Hadoop and HDFS are trademarks of The Apache Software Foundation.