Introduction
QueryIO provides a feature to associate Data Tags with files.
You can configure a database instance for use with each Namespace and the tags associated to each file are stored in this database.
This enables you to search for specific files as per the tags they've been associated with.
You can execute standard SQL queries on the database specifying the filters and retrieve a list of the files that pertain to your requirement.
QueryIO can stores two types of tags for a file:
Typically, the number of files stored in HDFS grows to the order of millions over a period of time.
It is recommended that you configure multiple database instances in such a way that the database instances and namenodes have one to one mapping with each other.
HDFS Core Metadata
Metadata (metacontent) is defined as data providing information about one or more aspects of the data.
The namespace of the entire filesystem, including the mapping of blocks to files and file system properties, is stored in HDFS.
Core Metadata refers to these properties that are stored in HDFS.
When you upload any files to QueryIO, it automatically extracts this HDFS metadata for those files from HDFS.
The extracted metadata is then stored in the associated table in the database.
Using the extracted metadata you can also reconstruct the file system namespace so that you do not loose access to your data even if your Namenode crashes.
Database schema for storing hdfs metadata is as follows:
|
Parameter |
Description |
Data Type |
Column Name |
File path |
Absolute path of the file on the cluster
|
String |
FILEPATH |
Access time |
The time when the file was last accessed
|
Timestamp |
ACCESSTIME |
Modification time |
The time when the file was last modified
|
Timestamp |
MODIFICATIONTIME |
Owner |
Name of the file owner
|
String |
OWNER |
User group |
User group to which the file belongs
|
String |
USERGROUP |
Permission |
Permissions of the file
|
String |
PERMISSION |
Block size |
Size of the blocks of the file
|
Integer |
BLOCKSIZE |
Replication |
Replication count for the file
|
Integer |
REPLICATION |
Length |
Length of the file in bytes
|
Integer |
LEN |
Compression Type |
Compression algorithm used for the file. Supported algorithms are SNAPPY, GZ, LZ4.
|
String |
COMPRESSION_TYPE |
Encryption Type |
Encryption algorithm used for the file. Supported algorithms are AES256
|
String |
ENCRYPTION_TYPE |
Data Tags
Every type of file has some associated properties with it that can help to make it searchable.
These properties includes such things as the name of the author or the date that the file was last modified.
These could be file specific, such as aspect ratio or dimensions of an image file.
QueryIO enables users to associate files in HDFS with these Data Tags that are not interpreted by HDFS.
QueryIO uses Apache Tika™ to parse and extract Data Tags from various files.
Following are some of the supported document formats whose parsers are pre-configured in QueryIO:
-
HyperText Markup Language
-
XML and derived formats
-
Microsoft Office document formats
-
OpenDocument Format
-
Apple iWorks Formats
-
Portable Document Format
-
Electronic Publication Format
-
Rich Text Format
-
Compression and packaging formats
-
Text formats
-
Audio formats
-
Image formats
-
Video formats
-
Java class files and archives
-
The mbox format
-
The DWG (AutoCAD) format
-
Font formats
-
Scientific formats
You can also register your own metadata parser to support other file formats.
If you do not want QueryIO to extract the metadata from the files during ingestion, you can disable the registered parser from the "Data Tag Parsers" view.
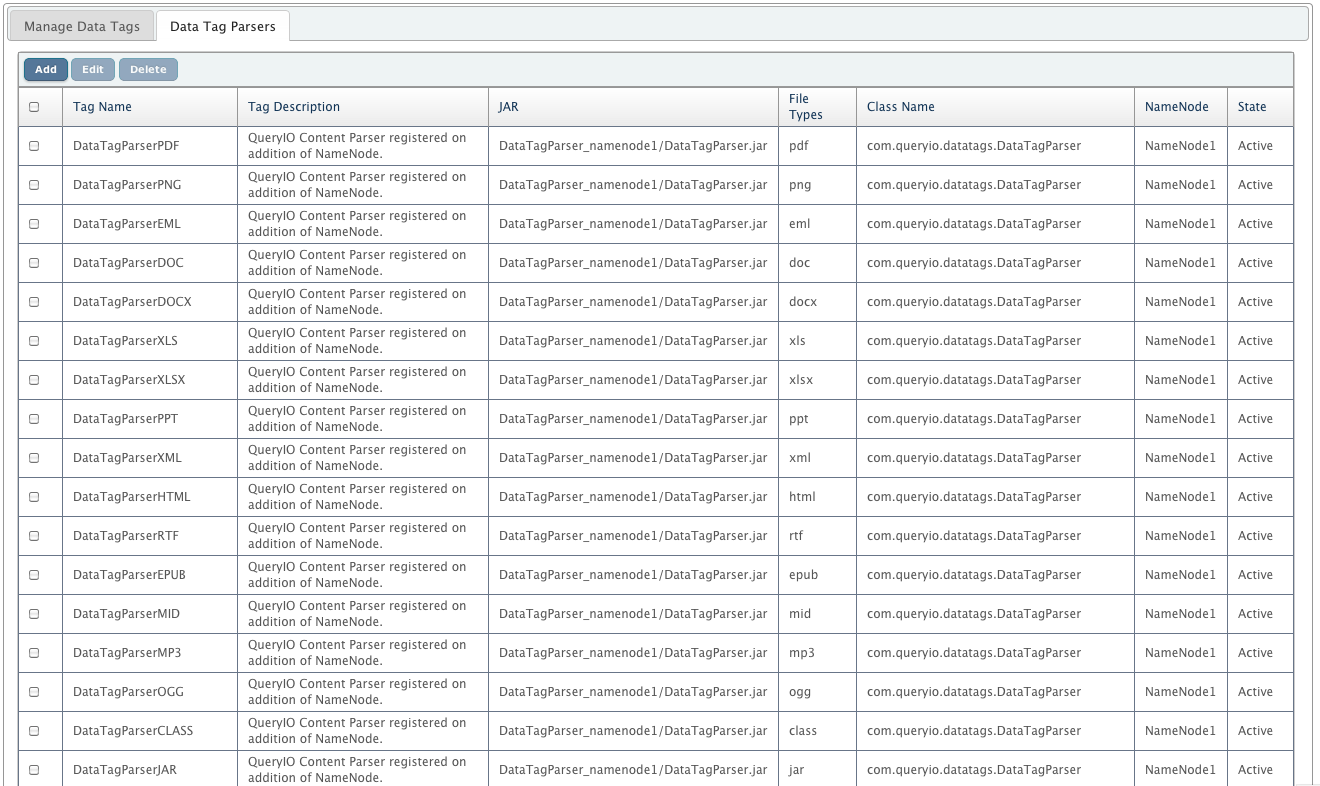
When you upload any file to HDFS using QueryIO, it automatically parses the file and stores the extracted Data Tags in the associated table (specific to file type) in the database.
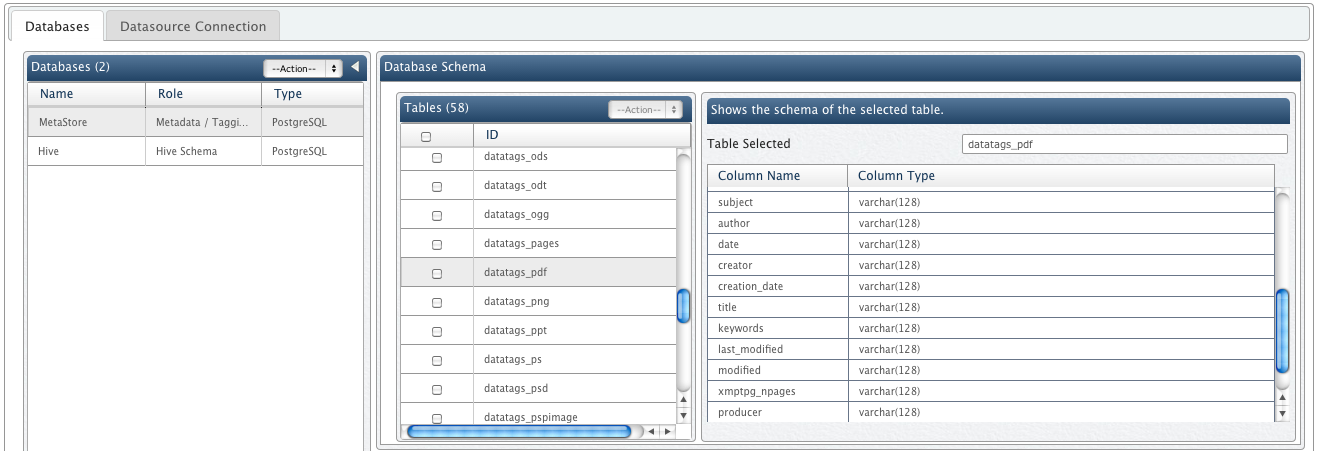
For instance, if you upload a PDF file to QueryIO, information like author, subject, number of pages, etc will be extracted from that file.
All of this extracted information will be saved in the respective columns in the 'datatags_pdf' table in the database.
You can view the schema for such a schema from "Manage Datasource" view.
Following is an example showing some of the columns / fields for 'datatags_pdf' table.
QueryIO supports custom data tags, that are meta-information attached to a file designed to be customized by the user.
These tags are stored in datatags table for its particular file type.
They are great for making searching easier because you can use words or even phrases that make sense to you.
You can think of these tags as keywords.
The value of the tag defined by the user can be any constant value, global function or an operator on any table column.
One can also define conditions based on which the data will be tagged.
Data tagging can be scheduled on-ingest or post-ingest.
You can choose to define data tags using the schema you have already defined using Hive DDL or can choose System defined schemas for different file formats.
To add a data tag, navigate to Data > Data Tagging view.
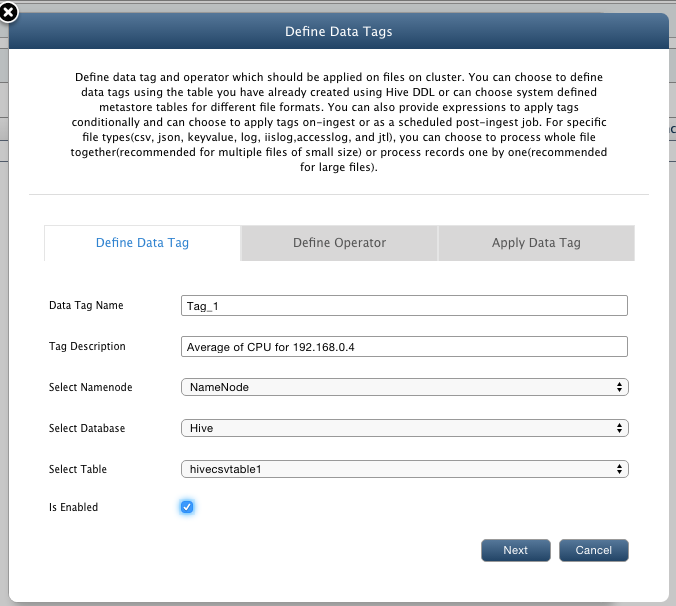
Following example guides you to add a data tag on a hive table : hivecsvtable1 which finds average reading of CPU in a particular file for host 192.168.0.4
- Click on Add button in the Data Tagging view to define a new Data Tag.
- Tag ID: Enter a unique ID for data tag which will be column name in your hive table. [For example : Tag_1]
- Tag Description: Provide description for this tag. [Say : Average of CPU for 192.168.0.4]
- Select NameNode: Select a namespace under which files will be parsed for tagging.
- Select Database: Select a database from Metastore database or Hive database on tables of which tags will be added. For our example, select Hive .
- Select Table: Select hivecsvtable1 table.
- Is Enabled: Check box to enable or disable the data tagging.
- Click on Next to define the operator and conditions.
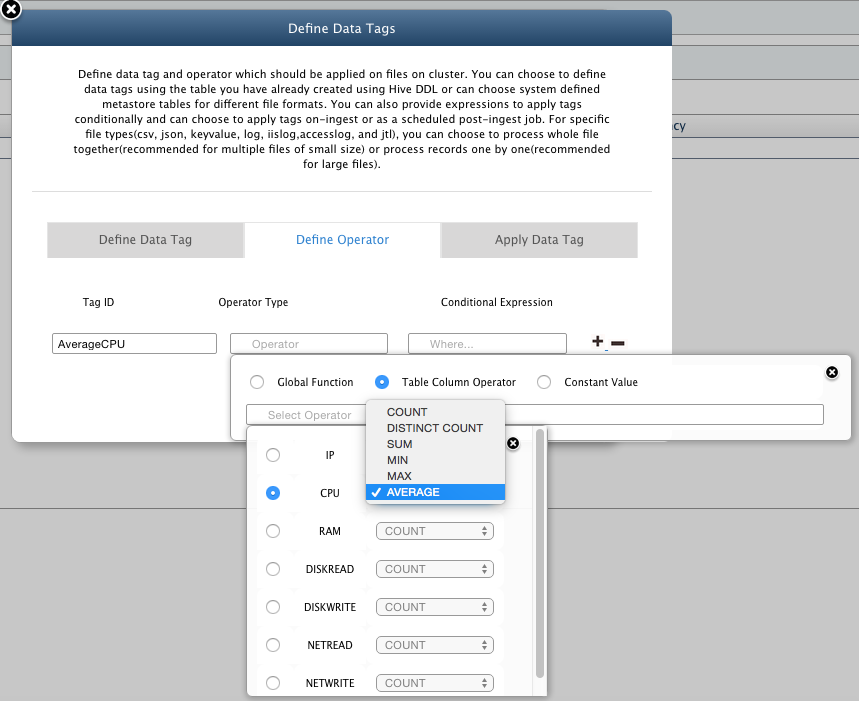
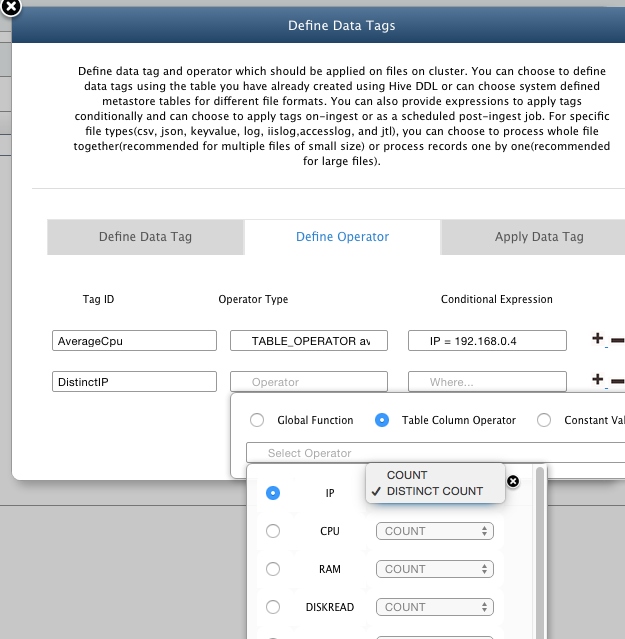
- Tag ID Enter a Tag Id which is the actual Field Name that identifies the Tag in queries.
- Operator Type: You can choose the tag value to be
- Global Function: Function applied on entire content of the file and resultant value is given to the tag.
- Table Column Operator: Operation is performed on a chosen column name from the defined schema and the resultant value is given to the tag (option not available in case no table is chosen).
- Constant Value: A single constant value is given to the tag.
For our example, select the "Table Column Operator" as "avg(CPU)"
- Conditional Expression: You can provide a compound expression that contains a condition on your data, which when evaluated to true would be included in the computation of Tag Value. Now to tag only those entries where IP is 192.168.0.4, use the wizard to easily define conditional expressions as "IP = 192.168.0.4".
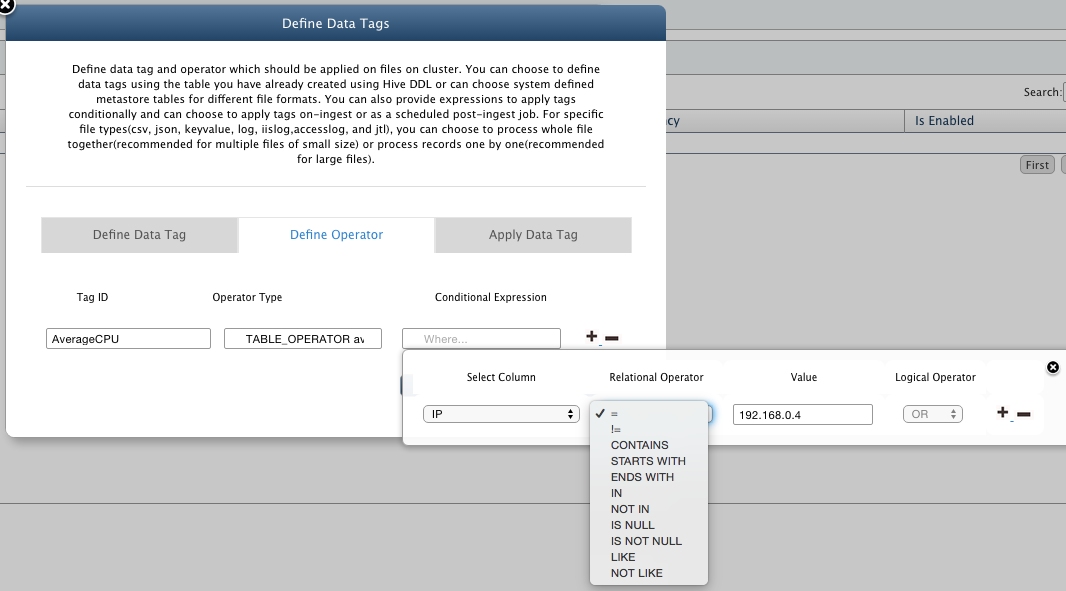
- To Add Multiple Tags On The Same Table Click on the plus(+) sign and provide the details for the Tag.
- Click on next to Schedule the data tag.
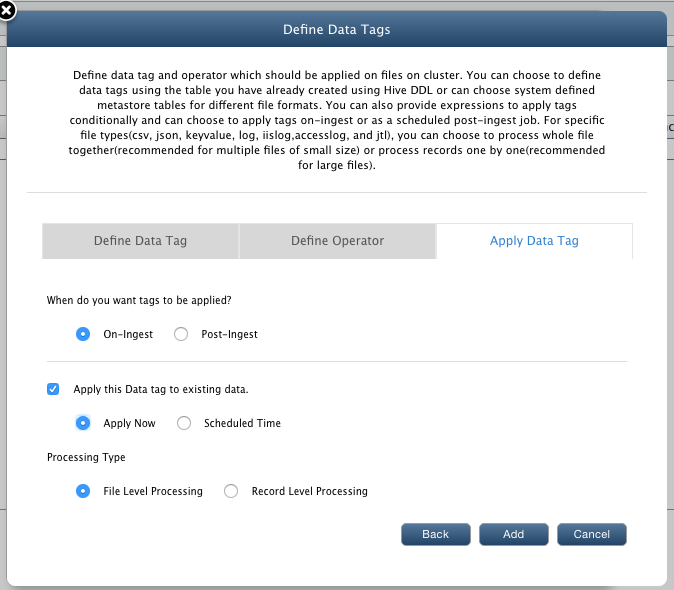
- When do you want data tags to be applied:
- On Ingest: Tagging job will be performed while importing files to QueryIO.
- Post-Ingest: Tagging job will be performed at chosen time intervals starting from a mentioned time.
- Apply this data tag to existing data: If checked then the tag will be applied to existing data when specified.
- Apply Now: Choose this to apply tag just after the data tag is defined.
- Schedule Time: Choose this to apply tag on specified time.
- Processing Type for Existing Data or Post-Ingest Tagging: For specific file types(csv, json, keyvalue, log, iislog,accesslog, and jtl), you can choose to process the file according to :
- File Level Processing: You can choose to process whole file together(recommended for multiple files of small size), a single mapper has lots of files.
- Record Level Processing: Process records one by one(recommended for large files),multiple mappers are launched and processing is done record by record.
- Click on Add to add newly created tag into tags list.
- Tag will be added to tags list and can be viewed in Data > Data Tagging.
You can use Data Import to import data to the cluster and check the tags added in metadata table using Query Designer
Copyright ©
Contact Us
Contact Us
2018 QueryIO Corporation. All Rights Reserved.
QueryIO, "Big Data Intelligence" and the QueryIO Logo are trademarks of QueryIO Corporation. Apache, Hadoop and HDFS are trademarks of The Apache Software Foundation.