In this chapter
MapReduce is a programming model for processing large data sets.
This document will show you how easily you can add and execute MapReduce jobs using QueryIO. It is assumed that you have already
configured ResourceManager and NodeManager nodes along with NameNode and DataNode.
QueryIO ships with MapReduce jobs for parsing LOG file types.
The job for LOG file types lets you search for particular messages or exceptions and inserts the results in the database.
LOG parser jobs is bundled in $INSTALL_HOME/demo/LOGParserMRJob.jar file.
QueryIO exposes various interfaces to allow traditional programmers to write their own custom MapReduce jobs.
To see how you can write your own MapReduce jobs, refer to the developer documentation.
This document will guide you through adding and executing MapReduce job for parsing LOG file types.
Adding MapReduce Job
- Go to Hadoop > MapReduce > Job Manager > Standard MapReduce tab.
- Click on Add button to add a new job. You will see the following window.
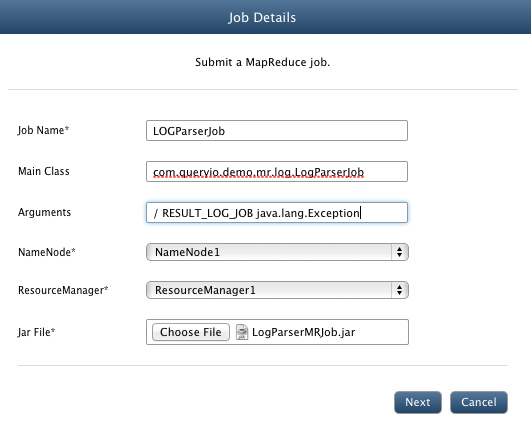
- In Job Name textbox, enter LOGParserJob.
- In Main Class textbox, enter the main class for your job. For LOG parser job, enter com.queryio.demo.mr.log.LogParserJob.
- In Arguments textbox, you can specify any argument that you want to pass to the main class of the job.
LOG parser job allows you to extract selected data from the LOG files using filter expressions.
The format for the argument is: [generic options] <input-folder> [<result-table-name>] [<search-string>] [<log-pattern>] [<start-time-ms>] [<end-time-ms>]
<input-folder>: Job parser will parse the contents of the directory specified by input-folder. Let it be / for the LOG parser job.
<result-table-name>: Name of the table in which result of the job execution will be saved.
<search-string>: String to be searched in files.
<log-pattern>: Project layout pattern string. Example: %d{dd MMM,HH:mm:ss:SSS} %C{3} - %m%n. Its not mandatory to provide log-pattern.
<start-time-ms> <end-time-ms>: Time between which logs will be parsed. Time must be specified in yyyy-MM-dd HH:mm:ss format.
Sample Arguments: / RESULT_LOG_JOB java.lang.Exception
- Select $INSTALL_HOME/demo/LOGParserMRJob.jar file.
- You can also add any dependent libraries and native files along with the job.
- For LOG parser job, we do not need to add any dependency libraries or files.
- Click Save.
Executing MapReduce Job
- Go to Hadoop > MapReduce > Job Manager > Standard MapReduce tab. Here you can see the list of jobs that you have added.
- Select the check box adjacent to the jobs that you want to execute. For LOG parser job, enable LOGParserMRJob checkbox.
- Click Start.
- You can also schedule jobs if you want to execute job after specific time interval.
- You can see the status of the job in the Jobs Execution History table.
Checking Job Status
- Go to Hadoop > MapReduce > Job Manager > Execution History tab.
- In the Jobs Execution History view, you can see the status of the jobs that you have submitted for execution.
You can use Query Designer to query the information extracted using MapReduce jobs.
Copyright © 2018 QueryIO Corporation. All Rights Reserved.
QueryIO, "Big Data Intelligence" and the QueryIO Logo are trademarks
of QueryIO Corporation. Apache, Hadoop and HDFS are trademarks of The Apache Software Foundation.