Post Ingest Data Tagging
This chapter explains on ingest big data analysis through UI and API.
What is Post Ingest Tagging
QueryIO supports post ingest data tagging.
This means that you can periodically execute data analysis procedures [parsers] to extract information from the data that you have imported.
This is achieved by scheduling the parsers to analyse data after a configurable time interval.
The parser is bundled in $INSTALL_HOME/demo/PostIngest.jar file. By default, this parser is
not registered.
Registering Data Tagger
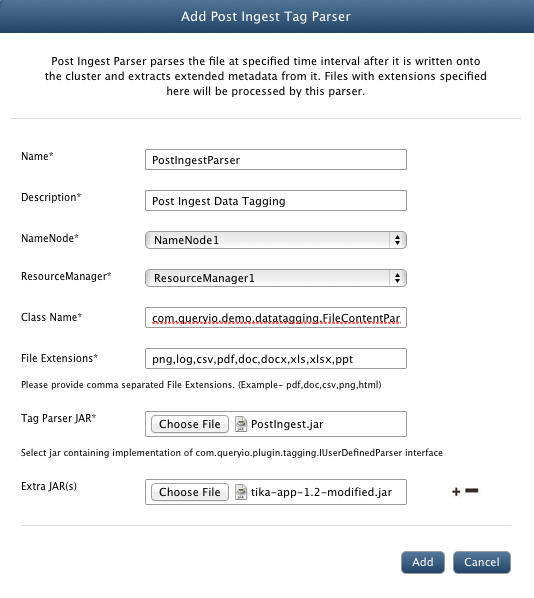
To register parsers for specific file types, follow the steps mentioned below.
- Go to Data > Data Tagging
- Click on Add button in the Post-Ingest view.
- In the Name textbox, enter name for the parser.
- In the Description textbox, enter suitable description for the parser.
- In the NameNode dropdown, select the NameNode on which data will be analyzed.
- In the ResourceManager dropdown, select ResourceManager to be linked with parser.
- Class Name: Provide main class for the parser. For sample parser, main class is com.queryio.demo.datatagging.FileContentParserr.
- File Extensions: Provide file extensions that you want to associate with the parser. [say png,log,csv,pdf,doc,docx,xls,xlsx,ppt]
- Tag Parser JAR: Click on Choose File to browse and select the $INSTALL_HOME/demo/PostIngest.jar parser JAR file.
- Extra JAR(s): To add any dependent JAR files, if required. You need to add a jar file for post ingest, $INSTALL_HOME/demo/tika-app-1.3-modified.jar.
- Click on Add to add the parser.
- Now you can start post ingest job directly from MapReduce > Job Manager > Standard MapReduce tab or you can schedule post ingest job using Admin > System Schedules > MapReduce Job tab section.
You can use Query Designer to query the metadata extracted using these parsers.
Copyright © 2018 QueryIO Corporation. All Rights Reserved.
QueryIO, "Big Data Intelligence" and the QueryIO Logo are trademarks
of QueryIO Corporation. Apache, Hadoop and HDFS are trademarks of The Apache Software Foundation.